快速入门¶
本教程围绕以下三个环节展开,帮助您快速掌握 msProf 工具在性能数据采集与分析中的基本用法:
- 环境准备:安装 msProf 工具并配置运行环境。
- 采集:通过 msProf 命令行工具,完成第一份性能数据的采集。
- 分析:基于生成的结果文件,展开初步的性能分析与瓶颈定位。
1. 相关文档¶
- 安装前请先阅读msProf 工具安装指南。
- 采集完成后如需进一步解析参数和场景说明,请参见msprof 解析工具。
- 若需要查看文件名和产物含义,请参见性能数据文件参考。
2. 开始前检查¶
开始操作前,建议先确认以下事项:
- 已安装 CANN Toolkit 开发套件包和 ops 算子包,并完成环境变量配置;若尚未安装,请先阅读msProf 工具安装指南。
- 当前环境具备可用 NPU,且计划用于保存性能数据的目录位于当前用户目录下,不使用软链接。
- 若希望直接复现附录中的
train.py样例,请提前准备可用的 Python、torch、torch_npu和torchvision环境。 - 若希望通过图形界面查看 Timeline,建议提前准备 MindStudio Insight;如尚未安装,可参考昇腾社区 MindStudio 下载 页面获取对应版本。
3. 环境准备¶
- 请先安装 CANN Toolkit 开发套件包和 ops 算子包(设备侧算子运行依赖),并完成环境变量配置。若尚未完成安装,请先阅读《msProf 工具安装指南》或参考 CANN 快速安装。
- 请确保当前环境具备可用 NPU,并已正确配置 CANN 相关环境变量。
- msprof 工具本身最低支持 Python 3.7.5。
- 若希望直接复现附录中的
train.py训练样例,推荐使用以下环境组合: - Python 3.9 及以上
- torch 2.7.1 及以上
- torch_npu 2.7.1 及以上
- torchvision 与 torch 匹配版本
torch、torch_npu和torchvision仅用于运行附录中的训练样例,不是 msprof 工具本身的必选依赖。若暂时只需要验证 msprof 安装与基础采集能力,可先跳过这部分依赖准备。-
执行以下命令设置环境变量:
-
运行以下命令验证 msprof 安装是否成功:
若希望继续复现附录中的 train.py 样例,可额外执行以下命令检查 Python 依赖与 NPU 运行环境:
```bash
# 查看Python版本
python3 --version
# 检查PyTorch依赖是否可导入,并确认NPU是否可见
python3 -c "import torch, torch_npu, torchvision; print(torch.__version__); print(torchvision.__version__); print(torch.npu.is_available())"
```
若上述 python3 -c 命令导入失败,或最终打印结果为 False,说明当前训练样例依赖或 NPU 运行环境尚未准备完成,请先完成对应环境修复后再继续运行 train.py。
4. 采集、解析并导出性能数据¶
- 先将附录中的 Resnet50 模型训练样例保存为当前目录下的
train.py,再执行以下命令,使用 msProf 工具拉起训练脚本并采集性能数据。
> [!NOTE]
>
- 上述
train.py脚本依赖torch、torch_npu和torchvision,建议使用 Python 3.9 及以上版本,并配套安装torch 2.7.1+、torch_npu 2.7.1+以及与torch匹配版本的torchvision。- --output:收集到的性能数据的存放路径。
- --application:待采集性能数据的用户程序。
- 以上为最基本的采集命令,如有其他采集需求,请参见msProf性能数据采集。
- 若脚本启动后未出现
[INFO] Using device: npu:0,通常表示torch_npu、NPU 设备或相关环境变量未准备完成,请先返回环境准备检查。
打印如下信息,则表示采集、自动解析已执行成功:
```bash
[INFO] Start profiling....
[INFO] Using device: npu:0
[Epoch 1/2] Average Loss: 2.4961
[Epoch 2/2] Average Loss: 2.2166
[INFO] Start export data in PROF_000001_20260323031749197_00815596RKPKAHRB..
...
[INFO] Export all data in PROF_000001_20260323031749197_00815596RKPKAHRB. done.
[INFO] Start query data in PROF_000001_20260323031749197_00815596RKPKAHRB..
Job Info Device ID Dir Name Collection Time Model ID Iteration Number Top Time Iteration Rank ID
NA host 2026-03-23 03:17:50.944273 N/A N/A N/A -1
NA 0 device_0 2026-03-23 03:17:50.954390 N/A N/A N/A -1
[INFO] Query all data in PROF_000001_20260323031749197_00815596RKPKAHRB. done.
[INFO] Profiling finished.
[INFO] Process profiling data complete. Data is saved in /home/prof_output/PROF_000001_20260323031749197_00815596RKPKAHRB.
```
- 命令执行完成后,在
--output指定的目录下生成PROF_XXX目录,存放自动解析后的性能数据。导出文件会随采集内容和参数不同而变化,以下列出最常见文件。
PROF_XXX
├── host // Host侧性能原始数据,快速入门阶段通常无需关注
│ └── data
├── device_{id} // Device侧性能原始数据,快速入门阶段通常无需关注
│ └── data
├── msprof_{timestamp}.db // db格式的性能数据
└── mindstudio_profiler_output // Host和各个Device的性能数据汇总
├── msprof_{timestamp}.json // chrome格式timeline数据
├── op_statistic_{timestamp}.csv // 按算子类型聚合的统计数据
├── op_summary_{timestamp}.csv // AI Core和AI CPU算子数据
└── ...
5. 性能分析¶
5.1 Timeline数据可视化¶
建议使用 MindStudio Insight 可视化工具加载 PROF_XXX 文件夹进行如下操作。若当前环境尚未安装 MindStudio Insight,可先参考昇腾社区 MindStudio 下载 页面完成安装。
- 打开 MindStudio Insight。
- 加载
PROF_XXX目录。 -
进入 Timeline 或 Summary 相关视图查看导出结果。
-
定位耗时较长的 API、算子及任务流
- 通过 HostToDevice 连线(表示主机侧向设备侧下发任务的关联关系)分析下发关系
MindStudio Insight工具详细介绍请参见《MindStudio Insight工具用户指南》。
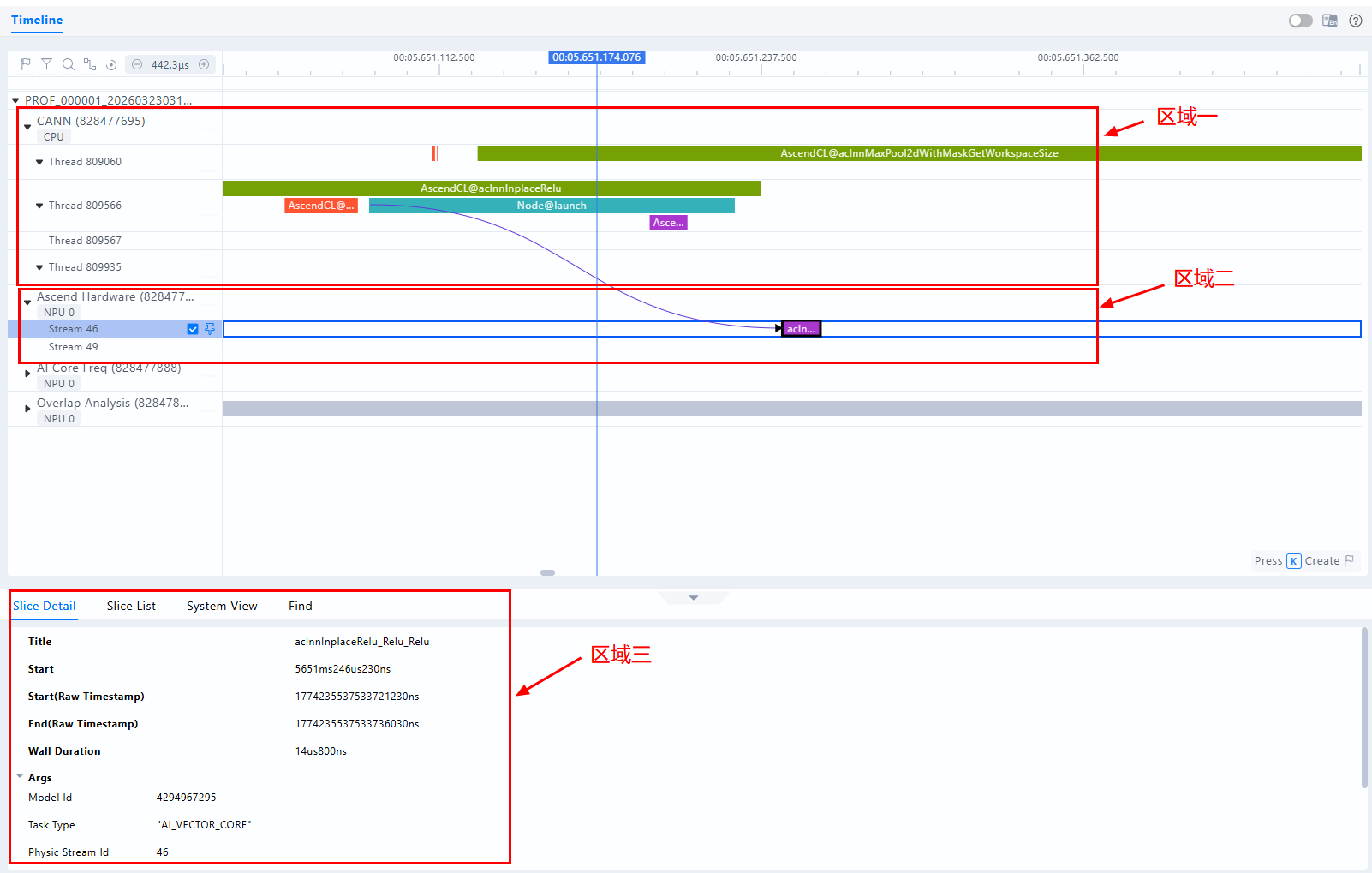
图1 msprof_*.json文件可视化呈现
区域1:CANN层数据(即 CANN ACL/Runtime等组件关键接口耗时)。 区域2:底层NPU数据,主要包含Ascend Hardware下各个Stream任务流的耗时数据和迭代轨迹数据、昇腾AI处理器系统数据等。 区域3:展示timeline中各算子、接口的详细信息(单击各个timeline色块展示)。
5.2 Summary数据分析¶
5.2.1 op_statistic_*.csv¶
若未生成 op_statistic_*.csv 文件,通常表示当前采集内容未包含对应的算子统计结果,或导出参数未覆盖该数据。
op_statistic_*.csv文件按照算子类型(Op Type)归类,给出各类算子的调用总时间、总次数等。快速入门阶段建议优先按 Total Time 排序,先定位耗时最长的算子类型,再判断这类算子是否有优化空间。
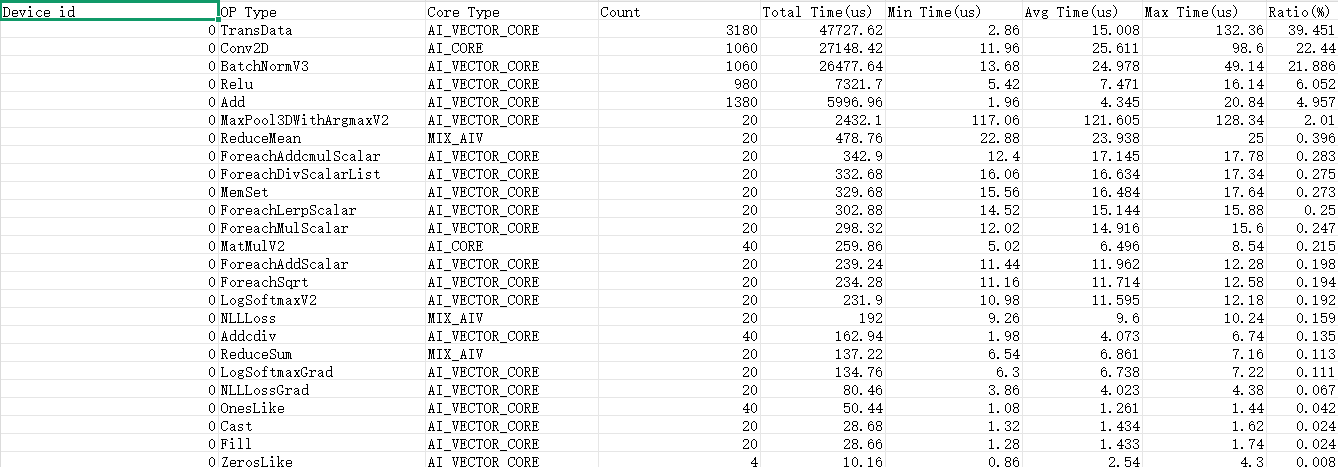
图2 op_statistic_*.csv文件示例
5.2.2 op_summary_*.csv¶
若未生成 op_summary_*.csv 文件,通常表示当前采集内容未包含对应的算子明细数据,或导出参数未覆盖该数据。
op_summary_*.csv文件包含算子的输入输出形状、PMU(Performance Monitoring Unit,性能监控单元)等详细信息,其中 Task Duration 字段记录算子耗时。快速入门阶段建议先按 Task Duration 排序定位高耗时算子,再按 Task Type 排序查看不同核(AI Core 和 AI CPU)上的耗时分布,从而识别出优先分析对象。

图3 op_summary_*.csv文件示例
6. 附录¶
Resnet50模型训练样例
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.models as models
class ResNet50:
def __init__(self, num_classes=1000, device=None):
if device is None:
if hasattr(torch, 'npu') and torch.npu.is_available():
self.device = torch.device("npu:0")
else:
raise RuntimeError(
"Current environment does not support NPU data collection. "
"Please check the Python, torch, torch_npu and torchvision versions. "
"Minimum supported: Python >= 3.7.5. "
"Quick start recommended: Python >= 3.9, torch >= 2.7.1, "
"torch_npu >= 2.7.1, torchvision matching torch."
)
else:
self.device = torch.device(device)
torch.npu.set_device(self.device)
print(f"[INFO] Using device: {self.device}")
# Use randomly initialized weights to avoid extra network or cache prerequisites.
self.model = models.resnet50(weights=None)
if num_classes != 1000:
self.model.fc = nn.Linear(self.model.fc.in_features, num_classes)
self.model = self.model.to(self.device)
def train(self, data_loader, epochs=1, lr=1e-4, freeze_backbone=False):
"""
Simple training function.
:param data_loader: torch.utils.data.DataLoader returning (images, labels)
:param epochs: Number of epochs to train for
:param lr: Learning rate
:param freeze_backbone: Whether to freeze the ResNet backbone, only training the classification head
"""
# Optionally freeze the backbone (useful for fine-tuning)
if freeze_backbone:
for param in self.model.parameters():
param.requires_grad = False
for param in self.model.fc.parameters():
param.requires_grad = True
# Optimize only parameters that require gradients
params_to_optimize = [p for p in self.model.parameters() if p.requires_grad]
optimizer = optim.Adam(params_to_optimize, lr=lr)
criterion = nn.CrossEntropyLoss().to(self.device)
self.model.train()
for epoch in range(epochs):
total_loss = 0.0
for inputs, labels in data_loader:
inputs, labels = inputs.to(self.device), labels.to(self.device)
optimizer.zero_grad()
outputs = self.model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(data_loader)
print(f"[Epoch {epoch + 1}/{epochs}] Average Loss: {avg_loss:.4f}")
def train():
trainer = ResNet50(num_classes=10)
fake_images = torch.randn(80, 3, 224, 224)
fake_labels = torch.randint(0, 10, (80,))
dataset = torch.utils.data.TensorDataset(fake_images, fake_labels)
loader = torch.utils.data.DataLoader(dataset, batch_size=8, shuffle=True)
trainer.train(loader, epochs=2, lr=1e-3, freeze_backbone=True)
if __name__ == "__main__":
train()